“การตลาดที่ดีต้องใช้งบเยอะ “
ประโยคนี้อาจจะเคยเป็นความจริงในยุคก่อน ที่การจะเข้าถึงลูกค้าได้ต้องผ่านสื่อใหญ่ๆ อย่างทีวี วิทยุ หรือป้ายบิลบอร์ดเท่านั้น ภาพจำของนักการตลาดที่ประสบความสำเร็จคือคนที่มีงบในมือเป็นล้านๆ เพื่อทุ่มซื้อโฆษณาให้คนเห็นเยอะที่สุด
แต่ในยุคนี้ แนวคิดดังกล่าวอาจไม่ใช่ทางเลือกเดียว ที่จะนำไปสู่ความสำเร็จอีกต่อไปแล้วนะครับ


แนวคิด Growth Hacking จากหนังสือ “Growth Hacking Marketing” ของ Ryan Holiday คือคำตอบสำหรับโลกการตลาดที่ไม่ได้มีแค่การทุ่มเงินอัดโฆษณาเพื่อยัดใส่ตาลูกค้าอีกต่อไป แต่มันคือแนวทางที่พิสูจน์ให้เห็นว่า “ความคิดสร้างสรรค์” และ “การใช้ข้อมูล” เพื่อสร้างสิ่งที่ลูกค้าต้องการและอยากบอกต่อนั้น ทรงพลังกว่าแค่การมี “เงิน” เยอะเพียงอย่างเดียว
เตรียมพบกับ Case Study จริงจากบริษัทอย่าง Hotmail, Dropbox, และ Airbnb ที่ทำการตลาดได้ปังสุดๆ โดยแทบไม่ต้องจ่ายค่าโฆษณา แล้วทุกคนจะรู้ว่าการตลาดที่ฉลาด ไม่จำเป็นต้องแพงเสมอไป!
การทำการตลาดแบบดั้งเดิม
ก่อนอื่นเรามาเจาะกันก่อนว่า ทำไมการตลาดแบบดั้งเดิมถึงไม่ได้ผลดี?
- มันคือการยิงกราด: การตลาดแบบเก่าเหมือนการเอาปืนกลมายิงกราดในฝูงชน หวังว่าจะโดนเป้าหมายสักคน ซึ่งมันเปลืองกระสุน (เงิน) อย่างมหาศาล
- มันวัดผลแทบไม่ได้: บริษัทที่ติดป้ายบิลบอร์ดไม่มีทางรู้เลยว่าคนที่ขับรถผ่านแล้วมาซื้อของมีกี่คน ROI (ผลตอบแทนจากการลงทุน) จึงเป็นเรื่องของการ “คาดเดา” ล้วนๆ
- มันน่ารำคาญ: คนยุคนี้เกลียดการถูกขัดจังหวะ เรามี Ad Blocker, เราจ่ายเงินเพื่อดู YouTube Premium แบบไม่มีโฆษณา, เราเรียนรู้ที่จะมองข้ามแบนเนอร์ไปโดยอัตโนมัติ การยัดเยียดโฆษณาจึงเป็นวิธีสร้างความรำคาญมากกว่าสร้างความภักดี
“แต่มันช่วยสร้าง Brand Awareness นะ”
นี่คือหนึ่งในประเด็นที่สำคัญที่สุดที่หนังสือเล่มนี้ได้ชี้ให้เห็น เวลาเราพูดถึงความคุ้มค่าของโฆษณาราคาแพง คำตอบที่เรามักจะได้ยินคือ “มันช่วยสร้าง Brand Awareness”
ซึ่งหนังสือ “Growth Hacking Marketing” ได้ท้าทายแนวคิดนี้อย่างสิ้นเชิง
ในมุมมองของ Growth Hacker ตามที่หนังสือได้อธิบายไว้ คำว่า “Awareness” เป็นตัวชี้วัดที่คลุมเครือและจับต้องได้ยาก หัวใจของ Growth Hacking คือการกระทำทุกอย่างต้องวัดผลและนำไปสู่การเติบโตได้จริง หนังสือเปรียบเปรยว่าการทุ่มเงินเพื่อสร้าง Awareness อย่างเดียวนั้น ไม่ต่างอะไรกับการไปตะโกนชื่อแบรนด์ของเรากลางสยามสแควร์
ถามว่ามีคนได้ยินไหม? ได้ยินแน่นอนครับ นั่นคือ Awareness แต่แล้วยังไงต่อ? มีคนเดินมาซื้อของของเราไหม? ใครคือคนที่ได้ยิน? พวกเขาสนใจสินค้าเราจริงหรือเปล่า?
คำตอบคือ เราไม่สามารถรู้ได้เลยครับ
สิ่งที่ Growth Hacker แสวงหา คือ Awareness ที่เกิดขึ้นในฐานะ “ผลพลอยได้” (Byproduct) ไม่ใช่การตั้งเป็นเป้าหมายหลักของการตลาด
Awareness ที่ดีและมีความหมายในแบบของ Growth Hacking เกิดจากการที่ลูกค้าใช้สินค้าของเราแล้วรักมันมากจนต้องไปบอกต่อเพื่อน, เกิดจากการแก้ปัญหาให้ลูกค้าได้จริงจนพวกเขาทวีตถึงเรา, หรือเกิดจากการสร้าง value ที่มากพอจนสื่อต่างๆ อยากเขียนถึงเราเอง “Marketing is the product” ซึ่งมันทั้งฟรีและทรงพลังกว่าหลายเท่าครับ
แล้วแนวคิด “Growth Hacking” คืออะไร
Growth Hacking เป็น “Mindset” หรือชุดความคิด ที่มีเป้าหมายเดียวชัดเจนคือ “การเติบโต” โดยทุกไอเดียต้องสามารถ
- ทดลองได้ (Testable)
- ติดตามผลได้ (Trackable)
- ขยายผลได้ (Scalable)
Growth Hacker คือส่วนผสมระหว่าง:
นักการตลาด + นักวิเคราะห์ข้อมูล + โปรแกรมเมอร์
พวกเขาไม่ได้คิดแคมเปญใหญ่ปีละครั้ง แต่จะตั้งคำถามเล็กๆ ทุกวัน เช่น “ถ้าเราเปลี่ยนสีปุ่มนี้ ยอดสมัครจะเพิ่มขึ้น 2% ไหม?” หรือ “เราจะสร้างฟีเจอร์อะไรที่ทำให้ลูกค้าต้องชวนเพื่อนมาใช้ให้ได้?” แล้วก็ลงมือทดลอง, เก็บข้อมูล, และเรียนรู้จากมันอย่างรวดเร็ว
Playbook ของ Growth Hacker
ขั้นตอนที่ 1: ทุกอย่างเริ่มต้นที่ Product-Market Fit (ไม่ใช่การตลาด)
ใน Playbook ของ Growth Hacker ไม่ได้เริ่มต้นคำถามว่า “จะโปรโมทสินค้ายังไง?” แต่จะเริ่มที่คำถามว่า “product ของเราดีพอแล้วหรือยัง?” นี่คือสิ่งที่เรียกว่า Product-Market Fit (PMF) ซึ่งเป็นเสาเอกของบ้าน ถ้าเสาไม่แข็งแรง การทุ่มเงินตกแต่งบ้าน (ทำการตลาด) ก็มีแต่จะทำให้บ้านพังเร็วขึ้น
หนังสืออธิบายว่า การตลาดไม่สามารถแก้ไข product ที่ห่วยได้ มันทำได้แค่เร่งกระบวนการตายของ product นั้นให้เร็วขึ้น เพราะยิ่งเราโปรโมทสินค้าที่ไม่ดีออกไปมากเท่าไหร่ ก็ยิ่งมีคนจำนวนมากเท่านั้นที่จะได้สัมผัสกับประสบการณ์แย่ๆ และบอกต่อในทางลบ
เคล็ดลับในการวัดและหา PMF:
- คุยกับลูกค้าอย่างจริงจัง: Ryan Holiday ย้ำว่าต้อง “ออกจากออฟฟิศ” ไปคุยกับผู้ใช้งานจริง สังเกตว่าพวกเขาใช้ product ของเราอย่างไร ส่วนไหนที่พวกเขาสับสน ส่วนไหนที่ทำให้ตาเป็นประกาย นั่นคือ insight ที่ประเมินค่าไม่ได้
- ใช้ “แบบสำรวจความผิดหวัง” ของ Sean Ellis: ถามคำถามสำคัญข้อเดียวกับผู้ใช้งานของเราว่า “คุณจะรู้สึกอย่างไรถ้าพรุ่งนี้สินค้า/บริการของเราหายไป?”
- ให้เลือกระหว่าง – ก. ผิดหวังมาก / ข. ค่อนข้างผิดหวัง / ค. ไม่รู้สึกอะไร
- ตามเกณฑ์ของ Sean Ellis ถ้ามีผู้ตอบว่า “ผิดหวังมาก” เกิน 40% นั่นคือสัญญาณที่ดีว่าเรากำลังเข้าใกล้ PMF แล้ว ถ้าไม่ถึง ก็แปลว่า product ของเรายังเป็นแค่ “ของที่มีก็ดี” แต่ไม่ใช่ “ของที่ขาดไม่ได้” และนั่นคือหน้าที่ที่เราต้องกลับไปแก้ไข
- หา “Aha! Moment” ให้เจอ: มันคือวินาทีที่ผู้ใช้ “เก็ท” และเห็น value และ ประโยชน์ที่แท้จริงของ product ของเรา หน้าที่ของเราคือออกแบบทุกอย่างเพื่อนำผู้ใช้ใหม่ไปสู่จุดนั้นให้เร็วและง่ายที่สุด
ขั้นตอนที่ 2: การหาลูกค้ากลุ่มแรก (Acquisition) แบบไม่หว่านแห
เมื่อเรามั่นใจในตัวผลิตภัณฑ์แล้ว ก็ถึงเวลาตามล่าหาลูกค้า หนังสือไม่ได้สอนให้เราไปซื้อโฆษณา Google Ads แต่สอนให้เราเป็นเหมือนนักสืบที่ต้องหาว่า ลูกค้ากลุ่มแรกของเราไปรวมตัวกันอยู่ที่ไหน แล้วนำ product ของเราไปเสนอให้ถูกที่ ถูกเวลา
Acquisition Strategy ที่น่าสนใจ:
- สร้าง Content ให้ความรู้ (Content Marketing): คือ แทนที่จะตะโกนว่า “ซื้อฉันสิ!” ให้เปลี่ยนเป็นการให้ความรู้หรือคุณค่าก่อน ตัวอย่างเช่น
- Mint.com เว็บไซต์จัดการการเงินส่วนบุคคล ก่อนที่ผลิตภัณฑ์จะเสร็จสมบูรณ์ พวกเขาสร้างบล็อกที่ให้ความรู้ด้านการเงินที่มีคุณภาพสูงและอ่านสนุก ทำให้พวกเขาสร้างฐานแฟนคลับและรวบรวมอีเมลจากผู้ที่สนใจได้มหาศาล เมื่อผลิตภัณฑ์เปิดตัว พวกเขาก็มีลูกค้ากลุ่มใหญ่รอใช้งานอยู่แล้ว
- ในไทยเองก็มีตัวอย่างที่ชัดเจนอย่างแบรนด์สกินแคร์ INGU โดยคุณอิงค์ (Ingck) ที่เริ่มต้นจากการสร้างคอนเทนต์ให้ความรู้เรื่องส่วนผสมสกินแคร์ในเชิงวิทยาศาสตร์จนได้รับนิยมและความน่าเชื่อถือสูง เมื่อคุณอิงค์สร้างฐานแฟนคลับที่เชื่อมั่นในความรู้ของแกได้แล้ว การเปิดตัวแบรนด์จึงไม่ใช่การเริ่มจากศูนย์ แต่เป็นการขายให้กับกลุ่มคนที่รอคอยและพร้อมจะซื้อทันที
- กลยุทธ์ขอยืม Traffic (Piggybacking): หาทางนำผลิตภัณฑ์ของเราไป “เกาะ” กับแพลตฟอร์มที่มีผู้ใช้งานจำนวนมากอยู่แล้ว ตัวอย่างเช่น
- PayPal เติบโตอย่างระเบิดเถิดเทิงด้วยการเป็นระบบจ่ายเงินที่น่าเชื่อถือที่สุดบน eBay (เว็บไซต์ประมูลสินค้าออนไลน์ที่ใหญ่ที่สุดในยุคนั้น)
- ส่วน Airbnb ก็ใช้วิธีสร้างเครื่องมือให้คนโพสต์ที่พักของตัวเองจาก Airbnb ไปยัง Craigslist (เว็บไซต์ชุมชนออนไลน์ขนาดใหญ่ของอเมริกาที่มีคนลงประกาศหาสินค้าและที่พักจำนวนมาก)ได้ง่ายๆ เพื่อดึงดูดทั้งผู้ให้เช่าและผู้เช่าจากแพลตฟอร์มยักษ์ใหญ่
- ทำในสิ่งที่ขยายผลไม่ได้ (Do Things That Don’t Scale): ในช่วงเริ่มต้น อย่าเพิ่งคิดถึงระบบอัตโนมัติหรือการ scale แต่จงใช้แรงเข้าสู้เพื่อเข้าถึงฐานผู้ใช้กลุ่มแรก และเรียนรู้จากพวกเขาให้ได้มากที่สุด ตัวอย่างเช่น
- Uber ที่ใช้วิธีส่งทีมงานไปตามงานอีเวนต์เกี่ยวกับเทคโนโลยีในซานฟรานซิสโก เพื่อเสนอให้ทดลองนั่งรถฟรีแก่ผู้เข้าร่วมงาน เป็นการเจาะกลุ่มเป้าหมาย (Tech Influencers) ที่แม่นยำและสร้างกระแสได้อย่างรวดเร็ว
- Reddit ในช่วงแรกเริ่ม ผู้ก่อตั้งได้สร้างบัญชีปลอมขึ้นมามากมายเพื่อโพสต์เนื้อหาและสร้างบทสนทนา ทำให้เว็บดูคึกคักและมีชีวิตชีวา จนดึงดูดผู้ใช้จริงให้เข้ามาร่วมวงได้สำเร็จ หรือ
ขั้นตอนที่ 3: ทำให้ลูกค้าติดใจและอยากบอกต่อ (Activation & Referral)
การดึงคนเข้ามาในร้านได้เป็นแค่ก้าวแรก หากอาหารไม่อร่อยหรือบริการไม่ดี เขาก็จะเดินจากไปและไม่กลับมาอีกเลย ขั้นตอนนี้คือการทำให้ลูกค้า “ติดใจ” และเปลี่ยนพวกเขาให้กลายเป็นนักการตลาดให้เรา
- ส่งผู้ใช้ให้ถึง “Aha! Moment” โดยเร็วที่สุด: นี่คือการสานต่อจากตอนหา PMF เมื่อเรารู้แล้วว่า “Aha! Moment” ของเราคืออะไร เราต้องออกแบบ User Experience ทั้งหมดเพื่อส่งผู้ใช้ไปให้ถึงจุดนั้น
- Facebook ค้นพบว่าผู้ใช้ที่จะอยู่กับพวกเขาต่อคือผู้ใช้ที่ “มีเพื่อนอย่างน้อย 7 คนภายใน 10 วันแรก” พวกเขาจึงทำทุกวิถีทาง เช่น สร้างฟีเจอร์ “คนที่คุณอาจจะรู้จัก” (People You May Know) เพื่อให้ผู้ใช้ใหม่บรรลุเป้าหมายนั้นให้ได้
- สร้างกลไกการบอกต่อฝังไว้ใน product (Built-in Virality): การบอกต่อที่ดีที่สุดคือการบอกต่อที่เป็นส่วนหนึ่งของการใช้ผลิตภัณฑ์ ไม่ใช่แค่แคมเปญชั่วคราว
- Hotmail ได้แทรกข้อความง่ายๆ พร้อมลิงก์ไว้ท้ายอีเมลว่า “P.S. I love you. Get your free email at Hotmail” ข้อความนี้ไม่ได้มาในรูปแบบแบนเนอร์โฆษณาที่น่ารำคาญ แต่มาในรูปแบบ “ป.ล.” (ปล. หรือ P.S.) ที่ให้ความรู้สึกเป็นกันเองเหมือนเพื่อนเขียนเสริมเข้ามาเอง ผลลัพธ์คือ ผู้รับสารไม่ได้มองว่ามันคือโฆษณา ทำให้เกิดการสมัครใช้งานต่อๆ กันไปเป็นทอดๆ
- Dropbox ใช้วิธี “ให้และรับ” (Dual-Sided Referral) ที่ทรงพลังทางจิตวิทยา เพราะผู้ชวนรู้สึกเหมือนกำลัง “มอบของขวัญ” ให้เพื่อน ไม่ใช่แค่การหลอกใช้เพื่อผลประโยชน์ตัวเอง
- Dropbox เปลี่ยนไอเดีย marketing campaign ทั่วไปจาก “ชวนเพื่อนมาใช้แล้ว คุณจะได้พื้นที่เพิ่ม 500MB” ซึ่งเวลาเราจะไปชวนเพื่อน ในใจเราจะรู้สึกตะขิดตะขวงเล็กน้อย มันเหมือนเรากำลังจะไป “หลอกใช้” หรือ “เอาเปรียบ” เพื่อนเพื่อผลประโยชน์ของตัวเอง
- โดย Dropbox ได้เปลี่ยนเกมทั้งหมดด้วยการเปลี่ยนเป็น “ชวนเพื่อนมาใช้ แล้ว คุณจะได้พื้นที่เพิ่ม 500MB และเพื่อนของคุณก็ได้ด้วย!” เพียงเท่านี้ การกระทำทั้งหมดก็เปลี่ยนไปทันที จากการ “เอาเปรียบ” กลายเป็นการ “มอบของขวัญ” หรือ “แนะนำสิ่งดีๆ” เราไม่ได้ทักเพื่อนไปในฐานะนักขาย แต่ทักไปในฐานะเพื่อนที่นำข่าวดีไปบอก กำแพงในใจของผู้ชวนจึงทลายลง การบอกต่อจึงเกิดขึ้นอย่างง่ายดายและจริงใจ
ขั้นตอนที่ 4: การรักษาฐานลูกค้าและสร้างการเติบโตซ้ำๆ (Retention & Optimization)
ธุรกิจที่ยั่งยืนไม่ได้วัดกันที่จำนวนลูกค้าใหม่ แต่วัดกันที่จำนวนลูกค้าที่ยังคงอยู่กับเรา หนังสือเปรียบเปรยว่าการหาลูกค้าใหม่โดยไม่สนใจลูกค้าเก่า ก็เหมือน “การพยายามเติมน้ำใส่ถังที่รั่ว” เติมเท่าไหร่ก็ไม่มีวันเต็ม
- สร้างลูปและทริกเกอร์เพื่อดึงลูกค้ากลับมา: ออกแบบผลิตภัณฑ์ให้มีเหตุผลที่ลูกค้าต้องกลับมาใช้งานซ้ำๆ Zynga ผู้สร้างเกม Farmville คือเจ้าพ่อในเรื่องนี้ พวกเขาสร้างลูปที่สมบูรณ์แบบ: พืชของคุณกำลังจะโต (ทริกเกอร์), คุณต้องกลับมาเก็บเกี่ยว (แอคชัน), คุณได้รับรางวัลและเลเวลอัพ (รางวัล), คุณลงทุนปลูกพืชชนิดใหม่ที่ใช้เวลานานขึ้น (การลงทุน) วนแบบนี้ไปเรื่อยๆ นอกจากนี้ยังใช้ Notification และภารกิจทางสังคม (ช่วยรดน้ำให้เพื่อน) เพื่อดึงคนกลับมาในเกมอย่างสม่ำเสมอ
- ใช้ Email Marketing อย่างชาญฉลาด: ไม่ใช่การส่งสแปมโปรโมชั่น แต่คือการส่งอีเมลที่ “ช่วยเหลือ” และ “มีความเกี่ยวข้อง” กับพฤติกรรมของผู้ใช้ เช่น อีเมลต้อนรับพร้อมไกด์การใช้งาน, อีเมลสรุปกิจกรรมประจำสัปดาห์, หรืออีเมลแจ้งเตือนเมื่อมีคนคอมเมนต์โพสต์ของเรา สิ่งเหล่านี้สร้างความผูกพันและทำให้ผลิตภัณฑ์ของเรายังคงอยู่ในใจลูกค้า
- หมกมุ่นกับข้อมูลเพื่อการพัฒนาไม่รู้จบ: Growth Hacker คือนักวิทยาศาสตร์ พวกเขาดูข้อมูลตลอดเวลาเพื่อหาทางปรับปรุง เช่น อัตราการเลิกใช้งาน (Churn Rate) ในแต่ละขั้นตอน, ฟีเจอร์ที่คนไม่เคยแตะเลย, หรือจุดที่ผู้ใช้คลิกรัวๆ ด้วยความสับสน (Rage Click) ข้อมูลเหล่านี้คือคำใบ้ที่นำไปสู่การปรับปรุงผลิตภัณฑ์ในเวอร์ชันต่อไป
บทสรุป
หลังจากอ่านทั้งหมดนี้ ทุกคนคงเห็นแล้วว่า Growth Hacking ไม่ใช่เรื่องของ “เงิน” แต่เป็นเรื่องของ “ความคิดสร้างสรรค์” และ “การใช้ข้อมูลวัดผล” มันคือการเปลี่ยนจากการตั้งคำถามว่า “เราจะซื้อโฆษณาที่ไหนดี?” ไปเป็นการตั้งคำถามว่า “สมมติฐานอะไรที่เราจะทดลองในสัปดาห์นี้เพื่อสร้างการเติบโต?”
ทุกคนสามารถเริ่มคิดแบบ Growth Hacker ได้ตั้งแต่วันนี้ ด้วยวงจรง่ายๆ ที่เรียกว่า สร้าง → วัดผล → เรียนรู้
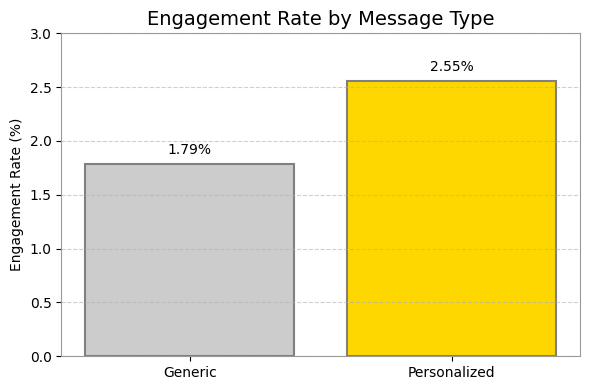
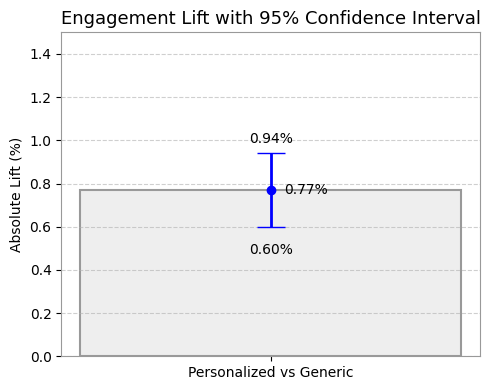
- ตั้งสมมติฐาน: เช่น “ฉันเชื่อว่าถ้าเปลี่ยนหัวข้ออีเมลให้เป็นคำถาม จะมีคนเปิดอ่านเพิ่มขึ้น 10%”
- ลงมือทดลอง (A/B Test): ส่งอีเมลสองแบบให้คนกลุ่มเล็กๆ เพื่อดูว่าสมมติฐานเป็นจริงหรือไม่
- วัดผลและเรียนรู้: ดูข้อมูลว่าผลลัพธ์เป็นอย่างไร? ถ้าเวิร์คก็นำไปใช้จริง ถ้าไม่เวิร์คก็ทิ้งมันไปแล้วลองสมมติฐานใหม่ วนแบบนี้ไปเรื่อยๆ
นี่แหละครับคือหัวใจของ Growth Hacking ที่ทำให้ธุรกิจไม่ว่าจะขนาดเล็กหรือใหญ่ สามารถสร้างการเติบโตที่วัดผลได้และสร้างความเปลี่ยนแปลงที่ยิ่งใหญ่ในโลกยุคใหม่
แล้วทุกคนล่ะครับ มีไอเดีย Growth Hacking อะไรเจ๋งๆ ที่อยากลองทำกับธุรกิจหรือโปรเจกต์ของตัวเองบ้าง? มาแชร์กันได้ใน comment นะครับ 😊🤍